

人工智能会胜过人类吗?2016年,谷歌开发的AlphaGo成为了首个击败围棋世界冠军的人工智能,向人类有力地证明了这一点。
此后,谷歌2017年又开发了“升级版”AlphaZero,它是一种可以从零开始,通过自我对弈强化学习在多种任务上达到超越人类水平的新算法,堪称“通用棋类AI”。
AlphaZero不仅擅长围棋,还擅长国际象棋和日本将棋,陆续击败了世界冠军级人物,可谓“多才多艺”,还登上了2018年的《科学》杂志封面。
现在,谷歌母公司Alphabet旗下的DeepMind又发布了一个更厉害的人工智能:MuZero。
与已经提前得知游戏规则的AlphaZero相比,这次的MuZero能够自动学习规则,并且在57款不同的雅达利游戏中取得了行业领先的表现,能够达到与AlphaZero在三种棋类中的表现相等的水平。
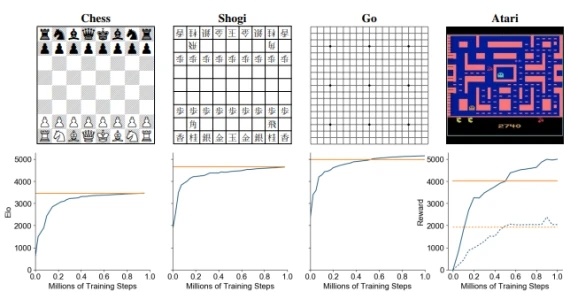
(图表:在国际象棋、围棋、围棋和雅达利的训练中MuZero达到的评价,y轴表示Elo等级)
此外,在围棋方面,MuZero的表现略优于AlphaZero,尽管它使用的总体计算较少。研究人员表示,这表明它可能对自己的处境有了更深入的了解。
MuZero将基于树的搜索与学习模型相结合(树是一种数据结构,用于从集合中定位信息),它接收到的是观测数据,比如棋盘或雅达利游戏的屏幕图像,这一点与人类下棋、玩游戏时的状态相同。
随后MuZero将会不断迭代更新观测到的数据,并且在每一步都使用模型预测接下来的策略(例如在哪里下棋)、价值函数(例如谁将得分)和即时奖励(如能够得到多少分)。
简单地说,MuZero自己探索出了游戏的规则,并在此基础上实行精确的规划。
DeepMind的研究人员解释,MuZero和AlphaZero的核心技术是强化学习的一种形式——即用奖励驱动人工智能朝着目标前进。
该模型将给定的环境建模为中间步骤,使用状态转换模型预测下一步,使用奖励模型预测奖励。
通常,基于模型的强化学习侧重于直接在像素级别对观察流进行建模,但是这种粒度级别在大规模环境中计算开销很大。
事实上,之前没有任何一种方法能够在视觉上很复杂的领域(如雅达利游戏)建立起一个便于进行规划的模型,即使在数据效率方面,结果也落后于经过调优的无模型方法。
该研究团队还重点观察了MuZero在围棋和游戏《吃豆小姐》中的表现。MuZero每步只有6次模拟——少于每步模拟的可能次数,不足以涵盖《吃豆小姐》中所有八种可能的行动——因此,它学会了一种有效的策略,并“迅速改进”。
研究人员表示,无论是在逻辑复杂的棋类游戏还是视觉上复杂的雅达利游戏中,MuZero的表现都能媲美此前的AI算法,并且胜过最先进的无模型(强化学习)算法。
AlphaGo的成功让越来越多人意识到了强化学习的激动人心之处。此前,机器学习领域顶级会议 NeurIPS 2019主办的Learn to Move 强化学习赛事中也出现了不少有意思的案例。
参赛者需要根据主办方提供的人体骨骼高仿模型中多达 100 多维以上的状态描述特征,来决定模型肌肉的信号,控制模型的肌体行走。赛事不仅要求模型的实时速度变换,还要360° 范围调整行走方向。
百度基于飞桨的强化学习框架PARL再度蝉联冠军,且将第二名拉下143分。百度的模型中甚至出现了一些普通人也难以做到的动作,如从立定状态突然平顺地向后转向并且同时以要求的速度行走,并全程保持稳定不会摔倒。
在这个领域内的成功有助于了解人体的运动机制,从肌肉层面学习控制仿生机器人的运动。

本报告前瞻性、适时性地对人工智能行业的发展背景、供需情况、市场规模、竞争格局等行业现状进行分析,并结合多年来人工智能行业发展轨迹及实践经验,对人工智能行业未来...
品牌、内容合作请点这里:寻求合作 ››


想看更多前瞻的文章?扫描右侧二维码,还可以获得以下福利:

下载APP

关注微信号





扫一扫下载APP
与资深行业研究员/经济学家互动交流让您成为更懂趋势的人
违法和不良信息举报电话:400-068-7188 举报邮箱:service@qianzhan.com 在线反馈/投诉 中国互联网联合辟谣平台
Copyright © 1998-2025 深圳前瞻资讯股份有限公司 All rights reserved. 粤ICP备11021828号-2 增值电信业务经营许可证:粤B2-20130734


