
当全球还在为DeepSeek的横空出世惊叹时,中国AI领域又悄然上演了一场更具颠覆性的技术革命。
据财联社报道,刚刚,李飞飞团队宣布,以不到50美元的云计算费用,成功训练了一个名为s1的人工智能推理模型。成本之低,令人咋舌!而且s1的表现却毫不逊色于OpenAI的o1和DeepSeek的R1等尖端推理模型。
但这还不是最炸裂的地方!
据前瞻经济学人产业观察组了解,s1模型的训练并非从零开始,其基座模型为阿里通义千问(Qwen)模型。也就是说,s1模型的神奇“低成本”,是建立在已具备强大能力的Qwen开源基础模型之上。
这意味着,中国又一个AI新王横空出世。
一.AI新王横空出世
2023年4月,阿里云正式推出通义千问(Qwen),选择了“全开源”策略,成为全球开发者关注的焦点。之后,阿里云进一步发布了Qwen2.5系列,包括多个尺寸的大语言模型、多模态模型、数学模型和代码模型。
今年大年初一凌晨,阿里云突放大招,悄悄升级发布通义千问旗舰版模型Qwen2.5-Max。
据其介绍,Qwen2.5-Max模型是阿里云通义团队对MoE模型的最新探索成果,预训练数据超过20万亿tokens,展现出极强劲的综合性能,在多项公开主流模型评测基准上录得高分,全面超越了目前全球领先的开源MoE模型以及最大的开源稠密模型。
与Qwen2.5-Max进行对比的模型,就包括了最近火爆海内外的DeepSeek旗下的V3模型。而在所有11项基准测试中,Qwen2.5-Max全部超越了对比模型。
下面这张图是测试结果,大家可以感受一下!

而李飞飞团队以不到50美元的云计算费用训练出的s1模型,正是以Qwen模型为基座,通过“蒸馏”技术而实现(该技术旨在通过训练模型来学习另一个人工智能模型的答案,从而提取其“推理”能力)。
对此,阿里云方面确认了这一消息。
阿里云回应称:“他们以阿里通义千问 Qwen2.5-32B-Instruct 开源模型为底座,在 16 块 H100 GPU 上监督微调 26 分钟,训练出新模型 s1-32B,取得了与 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型数学及编码能力相当的效果,甚至在竞赛数学问题上的表现比 o1-preview 高出 27%。”
其实,无论是火得一塌糊涂的DeepSeek,还是突然备受关注的Qwen,背后传递了两大信号:
一个是,中国团队正通过创新重新定义大模型的成本范式,彻底戳破了美国在AI领域遥遥领先的泡沫。

在DeepSeek诞生之前,成本过高是大模型应用没能快速铺开的一个主要困境。
大模型是比云还要烧钱的吞金兽。对于厂商来说,部署一个大模型需要面临高昂的硬件采购成本、模型训练成本以及日常运营成本。
其一,硬件采购成本。在国内,云计算技术人士公认的一个说法是,1万枚英伟达A100芯片是做好AI大模型的算力门槛。一块A100芯片的价格是1.5万美元(10.3万人民币),单硬件采购成本就超过10亿元。
其二,模型训练成本。ChatGPT一次完整的模型训练成本超过1200万美元(约合8000万元)。如果进行10次完整的模型训练,成本便高达8亿元。
其三,日常运营成本。数据中心内的模型训练需要消耗网络带宽、电力资源。此外,模型训练还需要算法工程师负责调教。上述成本也以亿元为单位计算。
也就是说,进入AI算力和AI大模型的赛道,前期硬件采购、集群建设成本就高达数十亿元。后期模型训练、日常运营以及产品研发成本同样高达数十亿元。根据行业内共识,生成式AI的投资规模高达百亿元。
而DeepSeek大模型以极低成本(600万美元)和少量芯片(2000块),实现了与OpenAI等巨头相媲美的性能,重构了人工智能行业的底层逻辑。
另一个是,大模型杀进“决赛圈”,底层操作系统或出现。
2024年,经过百模大战,基础大模型已“去九存一”。只有约10%的具有市场活力、用户活跃度高的大模型脱颖而出,进入到了决赛圈。
2025年,大模型的淘汰赛将继续,最终仅留下三四个产品,作为AI基础设施,但产品算力更强,迭代速度更快。李飞飞团队以Qwen模型为基座打造出s1模型,进一步凸显出这种趋势。
这不仅仅为大模型更丰富的应用打下了基础,同时有望推动成本进一步下探,进而引发可能比DeepSeek还恐怖的行业冲击。
02
谁有望成为“大模型第一城”
随着大模型竞赛加速,谁将有望晋升大模型第一城,成为新的城市之争。
前瞻产业研究院发布的报告显示,一线城市往往处于科技革命与产业升级的中心地带。从全国范围来看,我国人工智能产业形成了以京沪深杭为核心的聚集发展态势。

北京:基础研究雄厚+顶尖科研资源
截至2024年7月30日,北京有85款大模型数量在网信办备案,在全国占比超40%;代表大模型有百度的文心一言、百川智能的百川大模型等。
北京作为全国的科技文化中心,拥有众多顶尖高校和科研机构,如清华大学、北京大学、中国科学院等。这些机构在人工智能基础研究方面底蕴深厚,能为大模型的研发提供坚实的理论支持和人才储备。顶尖科研资源汇聚,使得北京在大模型的算法创新、理论突破等方面具有先天优势,有利于从源头推动大模型技术的发展。
上海:金融富矿+高度国际化
截至2024年7月30日,上海有43款大模型数量在网信办备案;代表企业有上海人工智能实验室和商汤科技等。
上海是国际金融中心,资本活跃且充裕,能够为大模型产业提供充足的资金支持,无论是初创企业的孵化,还是成熟企业的技术升级和规模扩张,都能得到资本的有力推动。高度国际化的环境,使上海更容易吸引国际先进技术、人才和企业,便于与全球大模型产业接轨,参与国际竞争与合作,引进国外先进经验和技术,提升自身在大模型领域的国际影响力。
深圳:创新应用领先+硬件产业链完备
据悉,深圳人工智能企业超过 2200 家,诞生了华为盘古系列大模型、腾讯混元大模型等。
深圳以创新应用领先著称,在人工智能应用场景的探索和落地方面具有丰富经验和强大的执行力。其完备的硬件产业链,为大模型与硬件设备的融合提供了得天独厚的条件,例如智能机器人、智能安防设备、智能家居等领域,能够实现大模型技术与硬件的深度结合,创造出以应用驱动为特色的大模型产业生态。
杭州:应用生态丰富+数字经济发达
杭州最近在大模型领域一时风光无两,上文所提及的DeepSeek和阿里云Qwen双双来自杭州。
杭州数字经济发达,拥有丰富的应用生态,特别是在电商、金融科技、云计算等领域占据领先地位。这为大模型提供了海量的数据资源和丰富的应用场景,有利于大模型进行针对性的训练和优化,开发出更符合市场需求的应用产品。尤其是,以余杭区为核心,数字经济产业发达,围绕阿里巴巴等企业形成了一定的产业生态,在电商、金融科技等领域有优势,能为大模型提供特色应用场景
尽管北上深杭在大模型领域都存在不同的领先优势,但也具有一定的短板,例如北京商业化落地场景不足、上海本土科技巨头缺失、深圳基础研究薄弱、杭州高端人才储备较一线城市不足。

未来已来!作为人工智能的重要发展方向,大模型正在逐渐成为未来科技发展的重要方向之一,各大城市必须给予高度重视。
作为更懂产业的科技型决策智库,前瞻产业研究院深耕行业研究26年,并帮助300+城市完成并落地2000+规划项目,在人工智能领域积累了深厚的经验。为了能够帮助地方政府既科学又前瞻更落地推动人工智能产业高质量发展,前瞻产业研究院特此成立了“前瞻人工智能产业规划所”,并独创性提出“前瞻人工智能产业高质量发展作战体系”,以严谨、科学、专业的态度来制定人工智能产业规划,最终以“一屏两案四清单”实施交付。

前瞻人工智能产业高质量发展作战体系
前瞻人工智能产业高质量发展作战体系包括“产业作战地图+产业情报中心+价值舱”三大板块。这一体系旨在通过科学的规划和持续优化,帮助区域实现人工智能产业的快速突破。
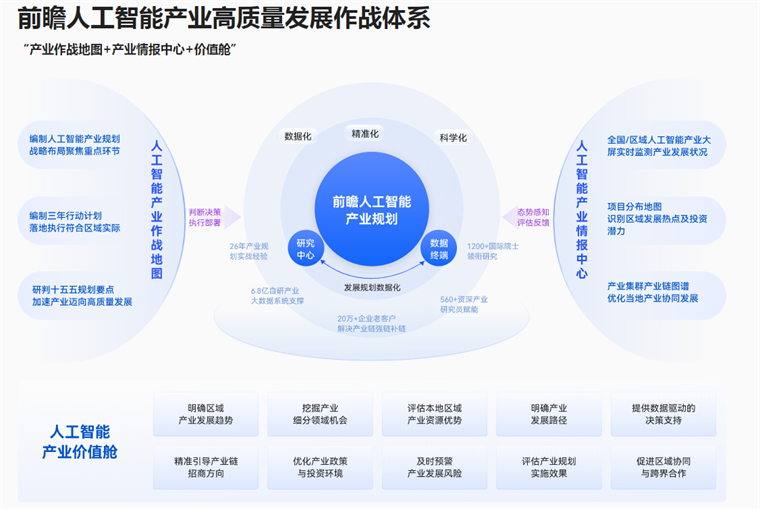
整体交付:“一屏两案四清单”
前瞻产业研究院通过“人工智能产业高质量发展作战体系”为产业规划底座,最终以为地方政府提供了一套科学、系统的人工智能产业规划解决方案。

展望未来,人工智能产业将是驱动中国经济的强引擎,也是各地政府竞相争抢的重要资源。前瞻产业研究院愿与地方政府携手合作,为强国建设和区域发展贡献智库力量。
前瞻经济学人APP 产业观察组
更多行业研究分析详见:
【1】《2025-2030年全球及中国多模态大模型行业发展前景与投资战略规划分析报告》,前瞻产业研究院
【2】《2025-2030年全球及中国大模型产业发展前景与投资战略规划分析报告》,前瞻产业研究院
同时前瞻产业研究院还提供产业新赛道研究、投资可行性研究、产业规划、园区规划、产业招商、产业图谱、产业大数据、智慧招商系统、行业地位证明、IPO咨询/募投可研、专精特新小巨人申报、十五五规划等解决方案。如需转载引用本篇文章内容,请注明资料来源(前瞻产业研究院)。
更多深度行业分析尽在【前瞻经济学人APP】,还可以与500+经济学家/资深行业研究员交流互动。更多企业数据、企业资讯、企业发展情况尽在【企查猫APP】,性价比最高功能最全的企业查询平台。
品牌、内容合作请点这里:寻求合作 ››


想看更多前瞻的文章?扫描右侧二维码,还可以获得以下福利:

下载APP

关注微信号





扫一扫下载APP
与资深行业研究员/经济学家互动交流让您成为更懂趋势的人
违法和不良信息举报电话:400-068-7188 举报邮箱:service@qianzhan.com 在线反馈/投诉 中国互联网联合辟谣平台
Copyright © 1998-2026 深圳前瞻资讯股份有限公司 All rights reserved. 粤ICP备11021828号-2 增值电信业务经营许可证:粤B2-20130734


