

作者|刘俊寰 来源|大数据文摘(ID:BigDataDigest)
前几日,清华大学官宣了前微软全球执行副总裁、人工智能与研究事业部负责人沈向洋的最新动态:加入清华大学高等研究院,以双聘教授的身份重新回归到大众的视线中。
由于疫情原因,3月5日,清华大学史上首次举行了线上聘任仪式,在“春风讲堂”系列讲座第四讲活动中,校长连线,远程完成了聘任仪式。沈向洋也发布了主题为“Engineering Responsible AI“的讲座。
在演讲开始前,清华大学校长邱勇对沈向洋的加入表示欢迎,并表示,“这是清华大学历史上第一次以视频会议的形式举行聘任仪式,校长连线发聘任书”。
其实早在2005年,沈向洋就首次受聘成为了清华大学高等研究院双聘教授,距今已经过去了15年,严格来说,这应该是“续聘”。
聘任仪式后,沈向洋在Zoom直播平台,用全英文进行了主题为Engineering Responsible AI的课程演讲,分享了他对目前AI可解释性与AI偏见相关的研究与看法。

文摘菌对演讲精华总结如下:
走出黑箱,构建可解释AI
演讲开始,沈向洋就表示,AI已经从科幻小说和电影中走入了现实,在金融、医疗等众多领域都已经得到了发展,但AI系统就像黑箱一样,我们不知道它为什么是基于什么标准做出的决策,这也就引出了第一个演讲主题:我们缺乏对AI所做决定的认知。
不过,沈向洋也指出,在人类历史发展过程中,每次新技术的开发,都会面临“如何让技术更加安全可靠”的问题。比如,在生产电气零部件时,我们都会有相应的检查记录。一旦哪里出现问题,我们需要对操作文件进行复盘,找出问题所在。但是,AI没有这种检修表,这就让我们对其中的问题更加迷茫。
因此AI的发展需要遵循一定的基本原则,包括公正、透明、可信赖&安全、隐私&安全、适用范围广泛、负责。

其实,很多年前,人类就已经在使用这种线性模式的系统了,只不过那时我们还不称其为AI。
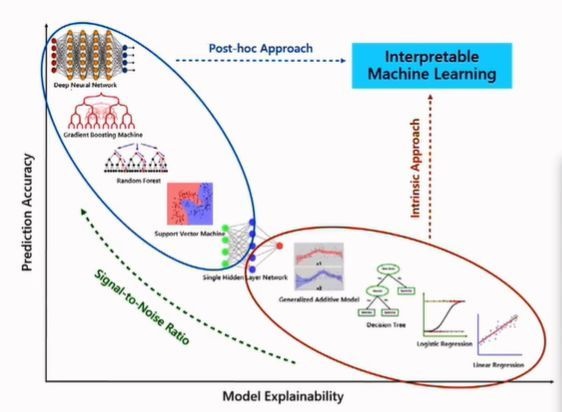
下面这张图是一张模型可解释性的变化图片,横轴代表模型的可解释能力,纵轴表示预测的准确性。以横轴为标准,越向右边延伸,模型的可解释性就越大;以纵轴为标准,越向上延伸,系统预测的准确性越高。
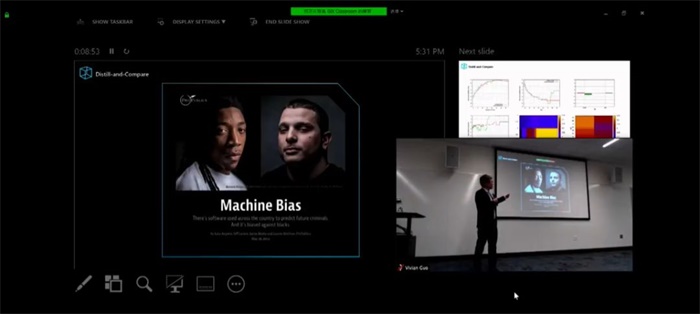
在2016年,很多地方都已经推出了用于预测未来罪犯的AI,法庭在审判时也已经开始用AI进行辅助判断,但我们越是把AI放在一个重要的位置上,就越会担心算法是否存在偏见。
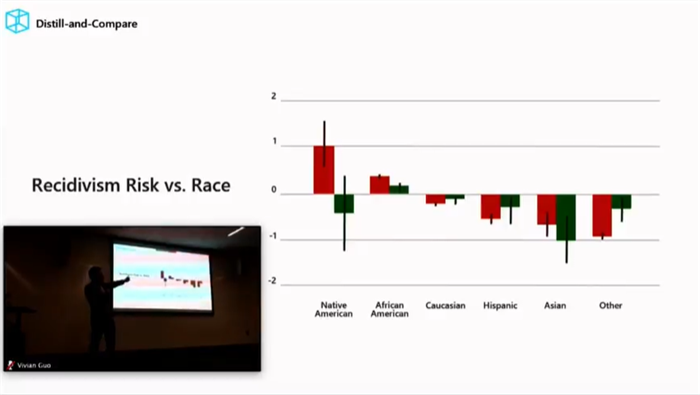
在下图中,红色曲线代表从模型提取的情况,绿色曲线代表实际情况。但问题是,你是根据什么判断这个人将会或将不会再次犯罪的?这时或许我们可以借用一下过去的数据,数据告诉我们,如果这个人有犯罪史,在过去他犯得罪越多,未来继续犯罪的可能性也就越高。

从下图可以看出,美国本土居民的犯罪率较高,对应地,根据红色柱形图显示,重新犯罪比率也比较高,但代表实际的绿线显示,结果与预测是相反的。
人们基于刻板印象,往往会认为非裔美国人犯罪率很高,实际上也并不是这样。
尽管得出这些结论,我们是严格基于事实和数据进行的预测,但是其中不可避免地存在着偏见,因此在训练和利用这种数据集的时候需要格外小心。
在举出第二个例子之前,沈向洋向大家安利了一篇名叫“why should I trust you?:explaining the predictions of any classlfler"的文章。他认为人工智能信任的关键的问题在于,我们理解黑箱中的东西,即使我们向里面输入后能够得到输出,但是我们仍无法理解模型本身是如何工作的。
有些人可能会提出一种看法,他们会说,这些难懂的模型我们不必追求整体解释,只需要局部的可解释性就行了,但是那么就会出现下列问题。
就算我们已经把模型的识别准确率训练到了5/6,但是仍然有可能无法识别这是哈士奇还是狼。如果你想要一只哈士奇,却把一只狼带回了家,那麻烦就大了。
从上面两个例子中可以看出,有时候你会以为,你已经训练出了一个非常强大的模型,但可能实际上并非如此,这就是为什么模型的可解释性如此重要的原因所在。

要解决AI的偏见需要从数据下手
现在我们一说到构建AI,就一定离不开数据。因此在了解AI的偏见源于何处的时候,我们也需要从源头,也就是数据本身下手。
纽约时报此前发过一篇文章,叫作”facial recognition is accurate, if you're a white guy",目前,在微软、IBM和Face++制定的面部识别算法中,黑人、女性的面部识别准确率普遍要低很多。

下图所示,黑色女性人脸识别的错误率高达21.073,很多人对此表示抗议。
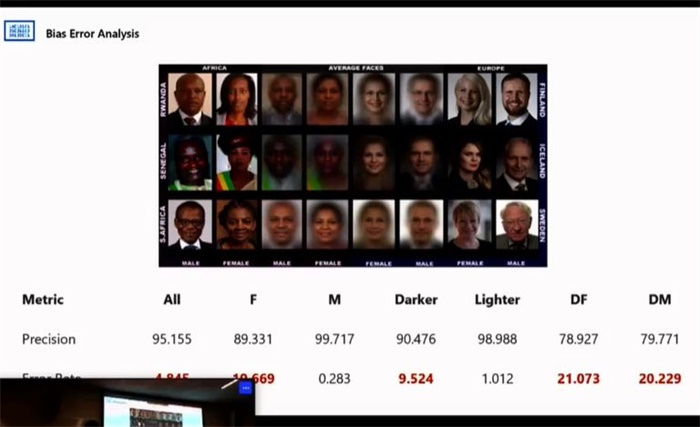
后来,对这个识别模型进行调整后,得到了如下结果:

可以看出,模型被改善之后,即使是面对不同肤色人种,识别准确率也有了明显的提高,许多分类错误率已经达到了0.000,即便是黑人女性,识别错误率也降低至1.9008。
从不断的训练中,沈向洋表示,他们得到的结论是:这种偏见来自于训练采用的样本数据。
基于这个问题,他们对微软500名机器学习领域工程师进行了调查,向他们询问是如何改善机器学习系统的?调查后得到的结论是,机器学习工程师面临的最大问题之一就是,有时候他们知道系统出问题了,但不知道具体是哪里,也并不知道为什么。
当训练一个或复杂或简单的模型时,最终得到了一个准确率为73.8%的结果,这个结果看上去似乎令人满意,但是一旦再深入训练的数据集时,会发现上述的一些问题,也就是说,在面对不同的肤色和性别,模型的准确率是不一样的。
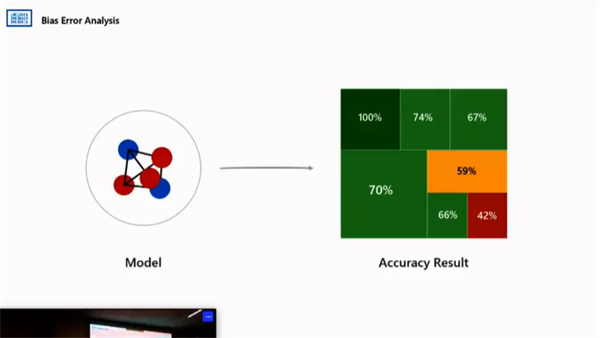
所以,沈向洋向大家介绍了一个方法,就是构建了一个系统来进行对比,找出具体问题所在。
传统机器学习系统是低级模式,现在的模型带有错误可解释性,可以从整体视角根据数据集不同的特征来判断问题源于何处,也可以从集群角度找出到底问题的原因。基于这种模型,一旦出现问题,可以复检样本数据集、模型来找出症结所在。

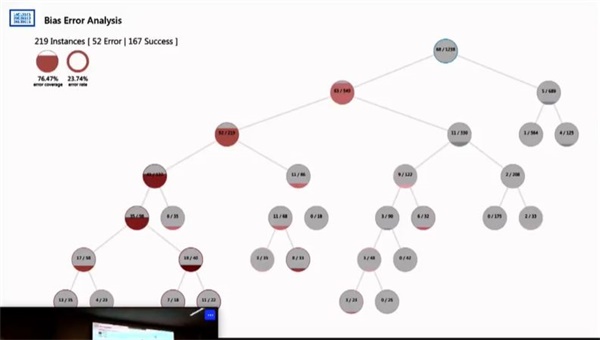
再次回到面部识别,在这个模型中,可以看到他的准确率达到了167/219,但是通过实际应用下来会发现,女性的识别准确度是不如男性的,同时,没有化妆的、短发的、不苟言笑的面部的识别准确率不够高。
这就表示你的模型出了问题,你需要重新回到数据上去,发现数据上存在哪些问题。
沈向洋表示,训练时他们使用了很多数据,通过列出27种职业,包括会计、律师、教师、建筑师等,然后输入一段话,系统可以识别出其职业为,如果修改了段落中某些单词,哪怕只改变很小的一部分 ,比如只修改了性别,最终的结果就从“教师”变成了“律师”。
这里就涉及到了文字嵌入几何学,这个几何嵌入有两个属性:Proximity和Parallelism。
比如当我们说到Apple和Microsoft,大家就会联想到,这两家公司都很伟大,他们的成立者是乔布斯和盖茨,这些就是嵌入的内容。

在比如说,下图的这张性别几何图中,可以看到,如果某个单词更向下邻近He,则表示为他;如果某个单词更向上,邻近She,表示为她。
从横轴可以看出,单词越向右,就越与性别无关;越向左,越与性别相关,例如妻子和丈夫,爸爸和妈妈。这里还可以看出,时髦通常用来形容女性,杰出通常用来形容男性。

至此,我们其实已经知道了问题出在哪里,其实,“时髦”、“杰出”、“天才”这些词,既可以用来形容男性,也可以用来形容女性。既然知道了问题所在,那么我们就可以用模型解决。
可以说,现在我们已经进入了AI时代,AI已经与我们的生活产生了十分紧密的关系,我们身为AI首代人,时代发展已经由不得我们自己做出选择是否接受AI,但是我们能决定我们可以用何种方式来构建AI以及使用AI。
最后,沈向洋表示,尽管计算机视觉现在很火,但未来十年自然语言处理或许会后来居上,“懂语言者得天下”,这也是沈向洋全程唯一说的中文。
编者按:本文转载自微信公众号:大数据文摘(ID:BigDataDigest),作者:刘俊寰
品牌、内容合作请点这里:寻求合作 ››


想看更多前瞻的文章?扫描右侧二维码,还可以获得以下福利:

下载APP

关注微信号





扫一扫下载APP
与资深行业研究员/经济学家互动交流让您成为更懂趋势的人
违法和不良信息举报电话:400-068-7188 举报邮箱:service@qianzhan.com 在线反馈/投诉 中国互联网联合辟谣平台
Copyright © 1998-2026 深圳前瞻资讯股份有限公司 All rights reserved. 粤ICP备11021828号-2 增值电信业务经营许可证:粤B2-20130734


