

(图片来源:摄图网)
4月24日,国产大模型厂商 DeepSeek(深度求索)正式推出DeepSeek-V4 预览版并同步开源,以100万token超长上下文、万亿级MoE架构、Agent能力拉满三大核心突破,直接对标国际顶尖闭源模型,成为当前开源领域最强模型之一。
DeepSeek-V4 按大小分为两个版本:deepseek-v4-pro和deepseek-v4-flash。Pro版本面向复杂推理与高精度任务,Flash 版本则主打规模化部署与快速响应。两个版本均支持最高100万token的上下文窗口,这在开源模型中尚属首次。
不过,DeepSeek坦言,受限于高端算力,目前Pro的服务吞吐十分有限。但好消息是,预计下半年昇腾950超节点批量上市后,Pro的价格将大幅下调。这意味着,国产算力的规模化部署正在从能用走向好用且便宜。
有分析认为,DeepSeek-V4 是二季度最受关注的国产模型事件,其国产化适配标志着国内“模型—芯片—云”闭环正逐步跑通,有助于形成自身AI商业闭环。模型越强、迭代越快,越会传导至AI芯片、设备与云基础设施环节,国产算力核心标的有望直接受益。
回顾DeepSeek的发展轨迹,堪称一部国产大模型的逆袭史。
2024年1月,DeepSeek正式发布首款通用大模型DeepSeek LLM,以67B参数、2万亿token训练数据夯实技术底座。
2024年5月,开源MoE架构的DeepSeek-V2,凭借高性能、低成本优势,获封“AI界拼多多”。同年12月,671B参数(MoE架构,激活37B)的DeepSeek-V3重磅开源,以约557.6万美元训练成本逼近GPT-4o能力,震惊业界。
2025年1月,DeepSeek发布推理模型DeepSeek-R1(比肩OpenAI o1),1月27日,其App同步登顶中美App Store免费榜,力压ChatGPT,成为改写全球AI格局的中国黑马。
DeepSeek 的成功,很大程度上得益于其极致的技术优化。2025年初国内主流大模型的训练成本普遍在数千万至数亿美元级别,其中百度文心、阿里通义、腾讯混元等大厂模型投入最高,基本超2亿美元。而创业公司如DeepSeek、Kimi等通过技术优化降低训练成本,降至3000-6000万美元之间。DeepSeek-V3的550万美元训练成本,至今仍是行业标杆。

中国大模型产业发展太快了!
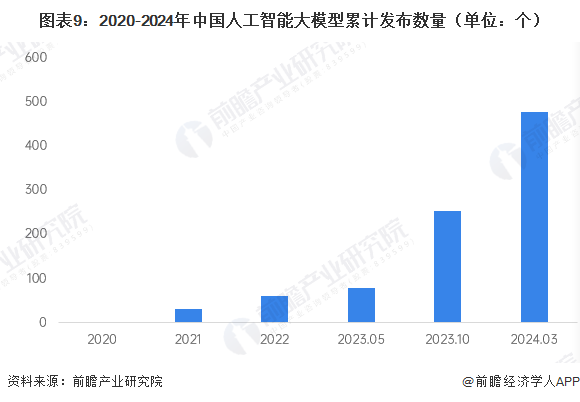
数据显示,截至2024年Q1,我国人工智能大模型累计发布数量达478个,当时排名仅次于美国。但追赶的速度远超预期。深圳市人工智能行业协会编制的《2025人工智能指数》显示,截至2025年7月,中国已成为全球发布大模型数量最多的国家,在全球3755个已发布大模型中,中国企业贡献了1509个,占比超过40%,数量位居全球首位。
今年4月,斯坦福大学人工智能研究所发布的最新一期《2026年人工智能指数报告》指出,当前中美顶级大模型差距“实质性消除”(effectively closed),头部模型间表现相当,呈并跑态势。报告显示,在前20的AI机构中,中国11家超过美国位居首位。阿里巴巴位列2025年全球顶级模型贡献榜第三名,同时也是入选重要模型最多的中国科技公司。
前瞻经济学人APP资讯组
更多本行业研究分析详见前瞻产业研究院《中国人工智能行业发展前景预测与投资战略规划分析报告》
同时前瞻产业研究院还提供产业新赛道研究、投资可行性研究、产业规划、园区规划、产业招商、产业图谱、产业大数据、智慧招商系统、行业地位证明、IPO咨询/募投可研、专精特新小巨人申报、十五五规划等解决方案。如需转载引用本篇文章内容,请注明资料来源(前瞻产业研究院)。
更多深度行业分析尽在【前瞻经济学人APP】,还可以与500+经济学家/资深行业研究员交流互动。更多企业数据、企业资讯、企业发展情况尽在【企查猫APP】,性价比最高功能最全的企业查询平台。

本报告前瞻性、适时性地对人工智能行业的发展背景、供需情况、市场规模、竞争格局等行业现状进行分析,并结合多年来人工智能行业发展轨迹及实践经验,对人工智能行业未来...
品牌、内容合作请点这里:寻求合作 ››


想看更多前瞻的文章?扫描右侧二维码,还可以获得以下福利:

下载APP

关注微信号





扫一扫下载APP
与资深行业研究员/经济学家互动交流让您成为更懂趋势的人
违法和不良信息举报电话:400-068-7188 举报邮箱:service@qianzhan.com 在线反馈/投诉 中国互联网联合辟谣平台
Copyright © 1998-2026 深圳前瞻资讯股份有限公司 All rights reserved. 粤ICP备11021828号-2 增值电信业务经营许可证:粤B2-20130734


